NotesWelcome to OpenHands (formerly OpenDevin), a platform for software development agents powered by AI.
OpenHands agents can do anything a human developer can: modify code, run commands, browse the web, call APIs, and yes—even copy code snippets from StackOverflow.Unfurl
NotesPaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools that help users train better models and apply them into practice.Unfurl
NotesConventional search methods rely on keyword matching, where the system locates exact words or phrases from the query within documents. This technique can be enhanced to better capture the context and intent behind the user's query, leading to more relevant and precise search results. Semantic search focuses on understanding the meaning and intent behind the query. Combining semantic search with filters—or additional parameters to narrow the results based on specific attributes—further improves accuracy.
In this article, we explore semantic search with filters and demonstrate how you can implement it using pgvector and JavaScript.FeedUnfurl
NotesAI isn't making our software dramatically better because software quality was (perhaps) never primarily limited by coding speed. The hard parts of software development – understanding requirements, designing maintainable systems, handling edge cases, ensuring security and performance – still require human judgment.
What AI does do is let us iterate and experiment faster, potentially leading to better solutions through more rapid exploration. But only if we maintain our engineering discipline and use AI as a tool, not a replacement for good software practices. Remember: The goal isn't to write more code faster. It's to build better software. Used wisely, AI can help us do that. But it's still up to us to know what "better" means and how to achieve it.FeedUnfurl
NotesNew, more powerful chips require entirely new methods to rack-mount, operate and cool them, and all of these parts must operate in sync, as overheating GPUs will die. While these units are big, some of their internal components are microscopic in size, and unless properly cooled, their circuits will start to crumble when roasted by a guy typing "Garfield with Gun" into ChatGPT.FeedUnfurl
NotesI hope that you now have a sense for word embeddings and the word2vec algorithm. I also hope that now when you read a paper mentioning “skip gram with negative sampling” (SGNS) (like the recommendation system papers at the top), that you have a better sense for these concepts.FeedUnfurl
NotesSo the problem Bluesky is dealing with is not so much a problem with Bluesky itself or its architecture, but one that’s inherent to the web itself and the nature of building these training datasets based on publicly-available data. Van Strien’s original act clearly showed the difference in culture between AI and open social web communities: on the former it’s commonplace to grab data if it can be read publicly (or even sometimes if it’s not), regardless of licensing or author consent, while on open social networks consent and authors’ rights are central community norms.FeedUnfurl
NotesSo, in summary: maybe people shy away from copilots because they’re tired of complexity, they’re tired of accelerating productivity without improving hours, they’re afraid of forgetting rote skills and basic knowledge, and they want to feel like writers, not managers.
Maybe some or none of these things are true - they’re emotional responses and gut feelings based on predictions - but they matter nonetheless.FeedUnfurl
NotesA newsletter from author Steven Johnson exploring where good ideas come from—and how to keep them from turning against us. Click to read Adjacent Possible, by Steven Johnson, a Substack publication with tens of thousands of subscribers.FeedUnfurl
NotesIn this guide we'll discuss:
Where and when fine-tuning can be useful.
Alternative approaches to extending the capabilities and behavior of pre-trained models.
The importance of data preparation.
How to fine-tune Mistral 7B using your own custom dataset with Axolotl.
The many hyperparameters and their effect on training.
Additional resources to help you fine-tune your models faster and more efficiently.FeedUnfurl
NotesWeb Applets are small, secure pieces of web code (bundles of HTML, JavaScript, and CSS) that can run anywhere, allowing a model to take actions within software much like a human would and then generate interfaces appropriate for the user’s intent. For example, a developer could write an applet that enables a model to respond to a query about local coffee shops by conducting internet searches and then displaying the results on an in-line map. And because the model can read the internal state of each applet, it can then conduct follow-up actions to complete a user’s request (for example, updating the map to display only coffee shops that will be open tomorrow afternoon). Anyone can build Web Applets and host them on the Web, and any client can potentially support them.Unfurl
NotesIf, as Marx argued, capital is dead labor, then the products of large language models might best be understood as dead speech. Just as factory workers produce, with their “living labor,” machines and other forms of physical capital that are then used, as “dead labor,” to produce more physical commodities, so human expressions of thought and creativity—“living speech” in the forms of writing, art, photography, and music—become raw materials used to produce “dead speech” in those same forms. LLMs, to continue with Marx’s horror-story metaphor, feed “vampire-like” on human culture. Without our words and pictures and songs, they would cease to function. They would become as silent as a corpse in a casket.FeedUnfurl
NotesOver the past month I’ve been exploring the rapidly evolving world of Large Language Models (LLM). It’s now accessible enough to run a LLM on a Raspberry Pi smarter than the original ChatGPT (November 2022). A modest desktop or laptop supports even smarter AI. It’s also private, offline, unlimited, and registration-free. The technology is improving at breakneck speed, and information is outdated in a matter of months. This article snapshots my practical, hands-on knowledge and experiences — information I wish I had when starting. Keep in mind that I’m a LLM layman, I have no novel insights to share, and it’s likely I’ve misunderstood certain aspects. In a year this article will mostly be a historical footnote, which is simultaneously exciting and scary.FeedUnfurl
NotesI’ve been having quite a bit of fun with the fairly recent LivePortrait model, generating deepfakes of my friends for some cheap laughs.FeedUnfurl
Notes Large language models (LLMs) have shown remarkable proficiency in generating text, benefiting from extensive training on vast textual corpora. However, LLMs may also acquire unwanted behaviors from the diverse and sensitive nature of their training data, which can include copyrighted and private content. Machine unlearning has been introduced as a viable solution to remove the influence of such problematic content without the need for costly and time-consuming retraining. This process aims to erase specific knowledge from LLMs while preserving as much model utility as possible. Despite the effectiveness of current unlearning methods, little attention has been given to whether existing unlearning methods for LLMs truly achieve forgetting or merely hide the knowledge, which current unlearning benchmarks fail to detect. This paper reveals that applying quantization to models that have undergone unlearning can restore the "forgotten" information. To thoroughly evaluate this phenomenon, we conduct comprehensive experiments using various quantization techniques across multiple precision levels. We find that for unlearning methods with utility constraints, the unlearned model retains an average of 21\% of the intended forgotten knowledge in full precision, which significantly increases to 83\% after 4-bit quantization. Based on our empirical findings, we provide a theoretical explanation for the observed phenomenon and propose a quantization-robust unlearning strategy to mitigate this intricate issue... Unfurl
NotesIt is nightmarish to me to read reports of how reliant on ChatGPT students have become, even outsourcing to the machines the ideally very personal assignment "briefly introduce yourself and say what you're hoping to get out of this class." It is depressing to me to read defenses of those students, particularly this one that compares an AI-written essay to using a washing machine in that it reduces the time required for the labor. This makes sense only if the purpose of a student writing an essay is "to have written an essay," which it is not. The teacher did not assign it as busywork. The purpose of an essay is to learn and practice communication skills, critical thinking, organization of one's own thoughts. These are useful skills to develop, even (especially!) if you do not go into a writing career. Unfurl
NotesThousands of Dubliners showed up for the city's much-anticipated Halloween parade on Thursday evening. They lined the streets from Parnell Street to Christchurch Cathedral, waiting for the promised three-hour parade that would "[transform] Dublin into a lively tapestry of costumes, artistic performances, and cultural festivities." A likely story. There was no parade, and never was one. Unfurl
NotesOasis takes in user keyboard input and generates real-time gameplay, including physics, game rules, and graphics. You can move around, jump, pick up items, break blocks, and more. There is no game engine; just a foundation model.Unfurl
NotesA more effective abstraction is conceptualizing vector embeddings not as independent tables or data types but as a specialized index on the embedded data. This is not to say that vector embeddings are literally indexes in the traditional sense, like those in PostgreSQL or MySQL, which retrieve entire data rows from indexed tables. Instead, vector embeddings function as an indexing mechanism that retrieves the most relevant parts of the data based on its embeddings.FeedUnfurl
NotesI released LLM 0.17 last night, the latest version of my combined CLI tool and Python library for interacting with hundreds of different Large Language Models such as GPT-4o, Llama, Claude and Gemini.FeedUnfurl
Notes Embeddings aren't exactly new, but they have become much more widely accessible in the last couple years. What embeddings offer to technical writers is the ability to discover connections between texts at previously impossible scales.FeedUnfurl
NotesGenerative AI is like if capitalism reinvented the fae. It’ll trick you into accepting its agreement and then it’ll steal your face and start speaking with your voice.EmbedUnfurl
NotesIlya Sutskever shared a list of 30 papers with John Carmack and said, “If you really learn all of these, you’ll know 90% of what matters today”FeedUnfurl
NotesThis is how we’re headed for another AI winter, just as we saw with the fall of data science, crypto, and the modern data stack. And that’s actually a good thing. The promoters will hop onto the next trendy buzzword, while the real producers will keep moving forward, building a more capable future for AI.FeedUnfurl
NotesHey everyone! Today I wanted to talk about the state of the internet, how artists and everyone is affected by AI slop and social media, and why I think everyone should have a personal website these days! Let's bring back the old school internet in new, fun, and creative ways! ^_^EmbedUnfurl
Notessqlite-lembed is a SQLite extension for generating text embeddings, meant to work alongside sqlite-vec. With a single embeddings model file provided in the .gguf format, you can generate embeddings using regular SQL functions, and store them directly inside your SQLite database. No extra server, process, or configuration needed!Unfurl
NotesThe most common use-case for vectors in databases is for K-nearest-neighbors (KNN) queries. You'll have a table of vectors, and you'll want to find the K closestUnfurl
NotesYou can use SQLite's builtin full-text search (FTS5) extension and semantic search with sqlite-vec to create "hybrid search" in your applications. You can combine results using different methods like keyword-first, re-ranking by "semantics", and reciprocal rank fusion. Best of all, since it's all in SQLite, experiments and prototypes are cheap and easy, no 3rd party services required!Unfurl
NotesThis tutorial covers the origins and uses of the BART model for text summarization tasks, and concludes with a brief demo for using BART with Paperspace Notebooks.Unfurl
NotesWe have entered an era of LLM democratization. By showing that smaller models can be highly effective, enabling easy experimentation, diversifying control, and providing incentives that are not profit motivated, open-source initiatives are moving us into a more dynamic and inclusive AI landscape. This doesn’t mean that some of these models won’t be biased, or wrong, or used to generate disinformation or abuse. But it does mean that controlling this technology is going to take an entirely different approach than regulating the large players.FeedEmbedUnfurl
NotesBut in calling these programs “artificial intelligence” we grant them a claim to authorship that is simply untrue. Each of those tokens used by programs like ChatGPT—the “language” in their “large language model”—represents a tiny, tiny piece of material that someone else created. And those authors are not credited for it, paid for it or asked permission for its use. In a sense, these machine-learning bots are actually the most advanced form of a chop shop: They steal material from creators (that is, they use it without permission), cut that material into parts so small that no one can trace them and then repurpose them to form new products.Unfurl
NotesIt’s possible that, in the future, we will build an A.I. that is capable of writing good prose based on nothing but its own experience of the world. The day we achieve that will be momentous indeed—but that day lies far beyond our prediction horizon. In the meantime, it’s reasonable to ask, What use is there in having something that rephrases the Web?FeedUnfurl
NotesSooner or later, every single conversation I have will be recorded and transcribed and I’ll be able to look back at it later – details from a phone call with the bank, in the hardware store asking a question, someone mentions a book at the pub, an idea in a workshop. Ignoring the societal consequences for a sec lol ahem… how should the app to manage all that chatter work?FeedUnfurl
NotesI'm training RNNs all the time and I've witnessed their power and robustness many times, and yet their magical outputs still find ways of amusing me. This post is about sharing some of that magic with you.FeedUnfurl
NotesDouglas Hofstadter, the Pulitzer Prize–winning author of Gödel, Escher, Bach, thinks we've lost sight of what artificial intelligence really means. His stubborn quest to replicate the human mind. FeedUnfurl
NotesWhat if the private pursuit of profit was—for a long time—proximate to improving the lot of humans but not identical to it? What if capitalism has gone feral, and started making moves that are obviously insane, but also inevitable? Unfurl
NotesZen19 is beating extremely strong amateurs, but it hasn't beaten professionals in games with no handicap yet. That said, now that we know that Zen19 is using Monte Carlo strategies, the reason why it seems to be getting stronger as it's fed more CPU time is revealed: these strategies are the most obviously parallelizable algorithms out there, and for all we know this exact version of Zen19 could end up becoming World Champion if a few more orders of magnitude of CPU time were made available to it.
Which would feel like a shame, because I was really looking forward to seeing us figure out how brains work. FeedEmbedUnfurl
NotesNow maybe you can see how science could have a successor: thalience would use objective truth as an artistic medium and merge subjectivity and objectivity in a creative activity whose purpose is the re-sanctification of the natural world. To believe in an uplifting and satisfying vision of your place in the universe, and to know that this vision is true (or as true as anything can be) would be sublime. Thalience would be an activity worthy of post-scientific humanity, or our own biological or post-biological successors.Unfurl
 Home - PaddleOCR Documentation
Home - PaddleOCR Documentation Implementing Filtered Semantic Search Using Pgvector and JavaScript
Implementing Filtered Semantic Search Using Pgvector and JavaScript The 70% problem: Hard truths about AI-assisted coding
The 70% problem: Hard truths about AI-assisted coding Godot Isn't Making it
Godot Isn't Making it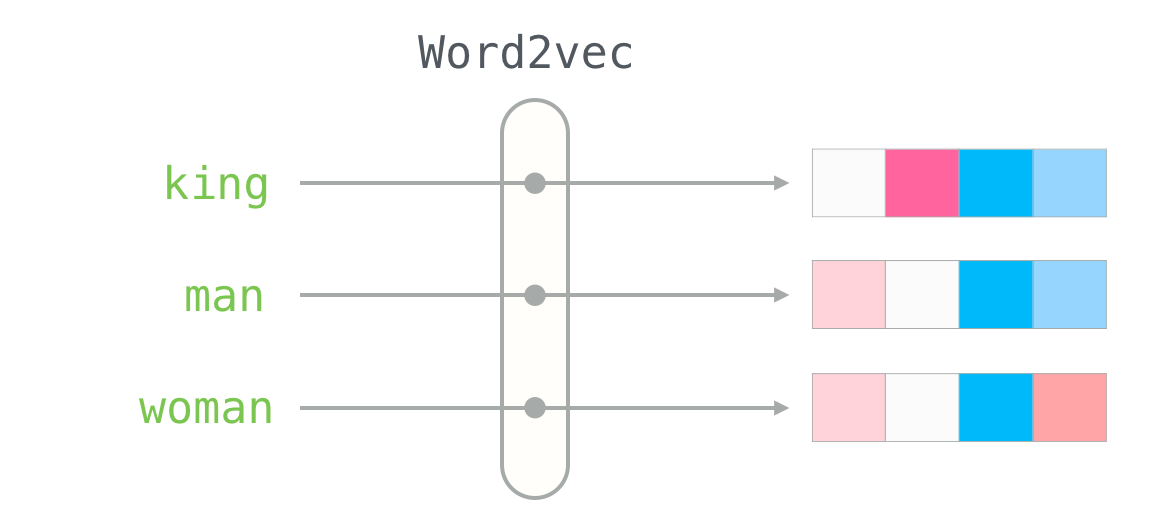 The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time.
The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time. Bluesky, AI, and the battle for consent on the open web
Bluesky, AI, and the battle for consent on the open web Between the Booms: AI in Winter – Communications of the ACM
Between the Booms: AI in Winter – Communications of the ACM Adjacent Possible | Steven Johnson | Substack
Adjacent Possible | Steven Johnson | Substack An introduction to fine-tuning LLMs at home with Axolotl • The Register
An introduction to fine-tuning LLMs at home with Axolotl • The Register Sponsoring the Web Applets project, an open approach to AI-empowered web apps - Mozilla Innovations
Sponsoring the Web Applets project, an open approach to AI-empowered web apps - Mozilla Innovations Dead Labor, Dead Speech - by Nicholas Carr
Dead Labor, Dead Speech - by Nicholas Carr Perceptually lossless (talking head) video compression at 22kbit/s | Martin Lumiste
Perceptually lossless (talking head) video compression at 22kbit/s | Martin Lumiste [2410.16454] Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge
[2410.16454] Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge Whatever AI Looks Like, It's Not | Defector
Whatever AI Looks Like, It's Not | Defector Thousands Turn Out For Nonexistent Halloween Parade Promoted By AI Listing | Defector
Thousands Turn Out For Nonexistent Halloween Parade Promoted By AI Listing | Defector Oasis
Oasis Vector Databases Are the Wrong Abstraction
Vector Databases Are the Wrong Abstraction You can now run prompts against images, audio and video in your terminal using LLM
You can now run prompts against images, audio and video in your terminal using LLM The A.I. Bubble is Bursting with Ed Zitron - YouTube
The A.I. Bubble is Bursting with Ed Zitron - YouTube Embeddings are underrated
Embeddings are underrated Aman's AI Journal • Primers • Ilya Sutskever's Top 30
Aman's AI Journal • Primers • Ilya Sutskever's Top 30 AI Winter Is Coming
AI Winter Is Coming Introducing sqlite-lembed: A SQLite extension for generating text embeddings locally | Alex Garcia's Blog
Introducing sqlite-lembed: A SQLite extension for generating text embeddings locally | Alex Garcia's Blog KNN queries | sqlite-vec
KNN queries | sqlite-vec Hybrid full-text search and vector search with SQLite | Alex Garcia's Blog
Hybrid full-text search and vector search with SQLite | Alex Garcia's Blog The case for handcrafted software in a mass-produced world • The Register
The case for handcrafted software in a mass-produced world • The Register Using Llamafiles for Embeddings in Local RAG Applications
Using Llamafiles for Embeddings in Local RAG Applications BART Model for Text Summarization
BART Model for Text Summarization Overview — Ray 2.34.0
Overview — Ray 2.34.0 Open-Source LLMs - Schneier on Security
Open-Source LLMs - Schneier on Security ChatGPT is not ‘artificial intelligence.’ It’s theft. | America Magazine
ChatGPT is not ‘artificial intelligence.’ It’s theft. | America Magazine AI-enhanced development makes me more ambitious with my projects
AI-enhanced development makes me more ambitious with my projects ChatGPT Is a Blurry JPEG of the Web | The New Yorker
ChatGPT Is a Blurry JPEG of the Web | The New Yorker Transcribing all our conversations 24/7 will be weird and also useful maybe (Interconnected)
Transcribing all our conversations 24/7 will be weird and also useful maybe (Interconnected) Self-Driving Cars Have a Secret Weapon: Remote Control | WIRED
Self-Driving Cars Have a Secret Weapon: Remote Control | WIRED Spotify’s Discover Weekly: How machine learning finds your new music
Spotify’s Discover Weekly: How machine learning finds your new music The Unreasonable Effectiveness of Recurrent Neural Networks
The Unreasonable Effectiveness of Recurrent Neural Networks The Man Who Would Teach Machines to Think - James Somers - The Atlantic
The Man Who Would Teach Machines to Think - James Somers - The Atlantic Computers are very good at the game of Go
Computers are very good at the game of Go Thalience — KarlSchroeder.com
Thalience — KarlSchroeder.com