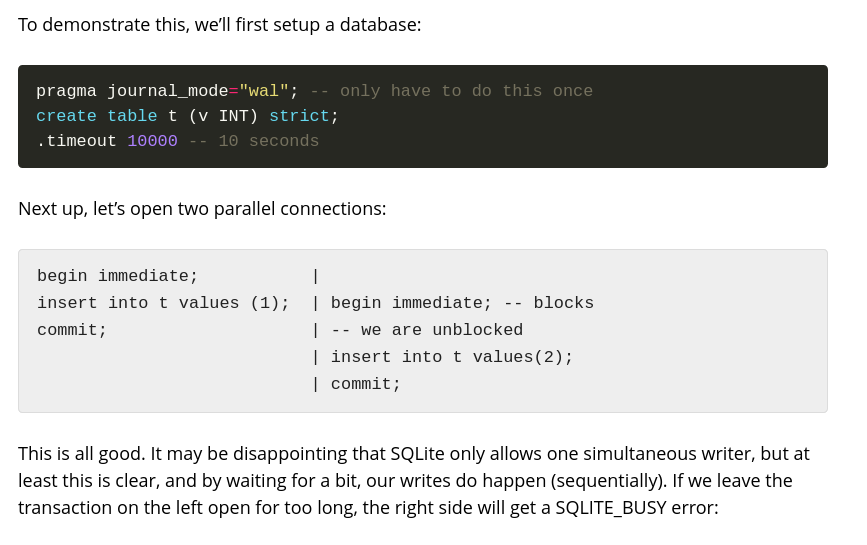
NotesThe tl;dr on this, to prevent SQLITE_BUSY errors even when setting a timeout, don’t ever upgrade transactions to read-write. If you know you are going to write in a transaction, use ‘BEGIN IMMEDIATE’, or start off with the write. But do read on for why this is so, and how other databases struggle with this problem as well.FeedUnfurl
NotesOn the Overture Slack, Jake Wasserman shared a cool trick where you can connect to a remote DuckDB database using the ATTACH statement, using an HTTP or S3 URL. Jake’s demo was especially cool because he created a DB containing only views referencing an Overture parquet on S3, so the hosted database file was only a couple hundred kilobytes.FeedUnfurl
NotesWe have used a query builder to programmatically build SQL queries, and by using higher-order functions (functions that take other functions as arguments) and pipelines, we have:
Eliminated the need to pass the query object explicitly.
Made it easier to add, remove, or rearrange query modifiers without disrupting the overall structure.
Improved maintainability and simplified testing since each query modifier function is a self-contained unit that can be reused across various queries and scenarios.Unfurl
Notes WeSQL is an innovative MySQL distribution that adopts a compute-storage separation architecture, with storage backed by S3 (and S3-compatible systems). It can run on any cloud, ensuring no vendor lock-in. Unfurl
NotesDB Browser for SQLite (DB4S) is a high quality, visual, open source tool designed for people who want to create, search, and edit SQLite or SQLCipher database files. DB4S gives a familiar spreadsheet-like interface on the database in addition to providing a full SQL query facility. It works with Windows, macOS, and most versions of Linux and Unix. Documentation for the program is on the wiki.FeedUnfurl
NotesAfter learning about indexes, I understood their basic structure, but I wanted to dig deeper — to explore the data structure, understand the algorithm, and learn how the index data is stored on disk.
The theory and actual implementation can differ, so I decided to explore this topic further.Unfurl
NotesA more effective abstraction is conceptualizing vector embeddings not as independent tables or data types but as a specialized index on the embedded data. This is not to say that vector embeddings are literally indexes in the traditional sense, like those in PostgreSQL or MySQL, which retrieve entire data rows from indexed tables. Instead, vector embeddings function as an indexing mechanism that retrieves the most relevant parts of the data based on its embeddings.FeedUnfurl
NotesToasty is an asynchronous ORM for the Rust programming language that prioritizes ease of use. Toasty supports SQL and NoSQL databases, including DynamoDB and Cassandra (soon).FeedUnfurl
NotesSometimes Litestream can be overkill for projects with a small database that do not have high durability requirements. In these cases, it may be more appropriate to simply back up your database daily or hourly. This approach can also be used in conjunction with Litestream as a fallback. You can never have too many backups!Unfurl
NotesWe’re building a general-purpose sync engine for the web. You put Zero in front of your existing database or web service, and we distribute your backend all the way to main thread of the UI.Unfurl
Notes"I guess what I’m saying is that my decision to use NoSQL, and I’m guessing others’ decisions to do so, has less to do with the fact that we can’t squeeze a few thousand writes a second out of MySQL and more to do with management and cost overhead. NoSQL solutions allow us to serve absurd amounts of data for a really, really low price. I’m happy to put my $/write, $/read, and $/GB numbers for my NoSQL setup against anyone’s RDBMS numbers.<br />
<br />
We’re not nearly as dumb as everyone thinks we are; I promise."FeedEmbedUnfurl
Notes"At Cloudkick we track a ton of metrics about our customer's servers and it's quite a challenge to store such massive amounts of data. Early on, we made the decision to avoid using tools like RRDTool, so we could provide a more holistic look at infrastructure. We had two firm requirements: we wanted to show trends on a macro-level and to have very low latency so our users would never wait for graphs to build. We initially used PostgreSQL, but as we added billions of rows, the performance quickly degraded. We used cron jobs that would roll up the data on intervals to trade storage for throughput and lower latency. With clever partitioning, we were able to stretch the system to a certain point, but beyond that we faced issues of needing a much bigger machine and faster rotational disks to accommodate our business requirements; that's when started looking at other solutions."Unfurl
Notes"Spatial indexing is increasingly important as more and more data and applications are geospatially-enabled. Efficiently querying geospatial data, however, is a considerable challenge: because the data is two-dimensional (or sometimes, more), you can't use standard indexing techniques to query on position. Spatial indexes solve this through a variety of techniques. In this post, we'll cover several - quadtrees, geohashes (not to be confused with geohashing), and space-filling curves - and reveal how they're all interrelated."Unfurl
Notes"One problem with the MySQL command line client is that queries with lots of columns tend to wrap crazily based on your terminal size. To overcome this, you can get a vertical output by terminating your queries with \G instead of ;. I find this format extremely helpful in cases where I know only one row will be returned. "Unfurl
Notes"The future for large websites’ data storage is likely a collection of special purpose data stores: GFS/MapReduce for batch jobs, inverted indexes for search and fast retrieval of small result sets and relational databases for smaller datasets which neeFeedUnfurl
NotesNoticing one thing missing from most tagging schemes: Preservation of the order of tags as entered with the item. Seems minor, but it's actually important for capturing intent.FeedUnfurl
Notes"And of course you could keep going with this novel “distributed” idea, and make this into an actually-distributed system, where individual users (or groups of them) can run their own Twitter servers that queue their incoming messages and relay theirUnfurl
Notes"Some of the best managed content I have ever seen sits on a Unix file system and some of the worst managed content I have ever seen sits in a big honking, breathtakingly expensive, relational database."Unfurl
Notes"The XML functions for PostgreSQL (introduced here) have been updated and, as of version 8, ship with the standard distribution of PostgreSQL." XSLT and XPath in the database.Unfurl
Notes"Ironically, a technology previously destined for the history books may well fit current and future requirements perfectly: the flat file." Er... since when were flat files going away?Unfurl
 What to do about SQLITE_BUSY errors despite setting a timeout - Bert Hubert's writings
What to do about SQLITE_BUSY errors despite setting a timeout - Bert Hubert's writings Turning Your Root URL Into a DuckDB Remote Database | Drew Breunig
Turning Your Root URL Into a DuckDB Remote Database | Drew Breunig Writing Composable SQL using Knex and Pipelines
Writing Composable SQL using Knex and Pipelines DB Browser for SQLite
DB Browser for SQLite SQLite Index Visualization: Structure
SQLite Index Visualization: Structure Vector Databases Are the Wrong Abstraction
Vector Databases Are the Wrong Abstraction Announcing Toasty, an async ORM for Rust | Tokio - An asynchronous Rust runtime
Announcing Toasty, an async ORM for Rust | Tokio - An asynchronous Rust runtime Database Remote-Copy Tool For SQLite
Database Remote-Copy Tool For SQLite Cron-based backup - Litestream
Cron-based backup - Litestream Zero
Zero SQLite Pragma Cheatsheet for Performance and Consistency | Clément Joly – Open-Source, Rust & SQLite
SQLite Pragma Cheatsheet for Performance and Consistency | Clément Joly – Open-Source, Rust & SQLite Sqlg Documentation
Sqlg Documentation Postgres.app | the easiest way to run PostgreSQL on the Mac
Postgres.app | the easiest way to run PostgreSQL on the Mac NoSQL vs. RDBMS: Let the flames begin! – stu.mp
NoSQL vs. RDBMS: Let the flames begin! – stu.mp tinydb.org
tinydb.org the ryan king » Introducing Conveyor
the ryan king » Introducing Conveyor