NotesAI isn't making our software dramatically better because software quality was (perhaps) never primarily limited by coding speed. The hard parts of software development – understanding requirements, designing maintainable systems, handling edge cases, ensuring security and performance – still require human judgment.
What AI does do is let us iterate and experiment faster, potentially leading to better solutions through more rapid exploration. But only if we maintain our engineering discipline and use AI as a tool, not a replacement for good software practices. Remember: The goal isn't to write more code faster. It's to build better software. Used wisely, AI can help us do that. But it's still up to us to know what "better" means and how to achieve it.FeedUnfurl
NotesNew, more powerful chips require entirely new methods to rack-mount, operate and cool them, and all of these parts must operate in sync, as overheating GPUs will die. While these units are big, some of their internal components are microscopic in size, and unless properly cooled, their circuits will start to crumble when roasted by a guy typing "Garfield with Gun" into ChatGPT.FeedUnfurl
NotesI hope that you now have a sense for word embeddings and the word2vec algorithm. I also hope that now when you read a paper mentioning “skip gram with negative sampling” (SGNS) (like the recommendation system papers at the top), that you have a better sense for these concepts.FeedUnfurl
NotesSo the problem Bluesky is dealing with is not so much a problem with Bluesky itself or its architecture, but one that’s inherent to the web itself and the nature of building these training datasets based on publicly-available data. Van Strien’s original act clearly showed the difference in culture between AI and open social web communities: on the former it’s commonplace to grab data if it can be read publicly (or even sometimes if it’s not), regardless of licensing or author consent, while on open social networks consent and authors’ rights are central community norms.FeedUnfurl
NotesSince everyone started using AI, more candidates started clearing the first round with flying colors. The platforms had to recalibrate to let in their target percentage. But they're not measuring the code written by the candidate anymore—they're measuring how well the candidate uses an LLM.
Most developers who can actually write this code try to do it themselves. They get marked lower than peers who used AI and completed it faster.
The result? Hiring teams keep raising the bar arbitrarily, trying to find the candidates who are best at prompt engineering their way through a coding test.Unfurl
NotesSo, in summary: maybe people shy away from copilots because they’re tired of complexity, they’re tired of accelerating productivity without improving hours, they’re afraid of forgetting rote skills and basic knowledge, and they want to feel like writers, not managers.
Maybe some or none of these things are true - they’re emotional responses and gut feelings based on predictions - but they matter nonetheless.FeedUnfurl
NotesA newsletter from author Steven Johnson exploring where good ideas come from—and how to keep them from turning against us. Click to read Adjacent Possible, by Steven Johnson, a Substack publication with tens of thousands of subscribers.FeedUnfurl
NotesThe current state-of-the-art Gemini model can fit roughly 1.5 million words in its context. That’s enough for me to upload the full text of all fourteen of my books, plus every article, blog post, or interview I’ve ever published—and the entirety of my collection of research notes that I’ve compiled over the years. The Gemini team has announced plans for a model that could hold more than 7 million words in its short-term memory. That’s enough to fit everything I’ve ever written, plus the hundred books and articles that most profoundly shaped my thinking over the years. An advanced model capable of holding in focus all that information would have a profound familiarity with all the words and ideas that have shaped my personal mindset. Certainly its ability to provide accurate and properly-cited answers to questions about my worldview (or my intellectual worldview, at least) would exceed that of any other human. In some ways it would exceed my own knowledge, thanks to its ability to instantly recall facts from books I read twenty years ago, or make new associations between ideas that I have long since forgotten. It would lack any information about my personal or emotional history—though I suppose if I had maintained a private journal over the past decades it would be able to approximate that part of my mindset as well. But as reconstruction of my intellectual grounding, it would be unrivaled. If that is not considered material progress in AI, there is something wrong with our metrics.Unfurl
NotesIn this guide we'll discuss:
Where and when fine-tuning can be useful.
Alternative approaches to extending the capabilities and behavior of pre-trained models.
The importance of data preparation.
How to fine-tune Mistral 7B using your own custom dataset with Axolotl.
The many hyperparameters and their effect on training.
Additional resources to help you fine-tune your models faster and more efficiently.FeedUnfurl
NotesWhile the ethics of this technology’s ecological and social impact are debated, use of the technology comes with repeated controversy. This instance of AI-assisted art from the company that made the award-winning Star Realms deck-building game has caused some to take to social media in disappointment and frustration. A few fans of the company state they won’t purchase another game by Wise Wizard, with at least one store stating it will no longer be stocking the company’s products. This anti-AI sentiment is not unanimous, however. Projects like Wonders of the First, Grimcoven, and Terraforming Mars still raised millions of dollars from thousands of backers as recently as June of this year — giving crowdfunding platforms an incentive to keep AI projects on the site, as long as the money is still there.FeedUnfurl
NotesWeb Applets are small, secure pieces of web code (bundles of HTML, JavaScript, and CSS) that can run anywhere, allowing a model to take actions within software much like a human would and then generate interfaces appropriate for the user’s intent. For example, a developer could write an applet that enables a model to respond to a query about local coffee shops by conducting internet searches and then displaying the results on an in-line map. And because the model can read the internal state of each applet, it can then conduct follow-up actions to complete a user’s request (for example, updating the map to display only coffee shops that will be open tomorrow afternoon). Anyone can build Web Applets and host them on the Web, and any client can potentially support them.Unfurl
NotesIf, as Marx argued, capital is dead labor, then the products of large language models might best be understood as dead speech. Just as factory workers produce, with their “living labor,” machines and other forms of physical capital that are then used, as “dead labor,” to produce more physical commodities, so human expressions of thought and creativity—“living speech” in the forms of writing, art, photography, and music—become raw materials used to produce “dead speech” in those same forms. LLMs, to continue with Marx’s horror-story metaphor, feed “vampire-like” on human culture. Without our words and pictures and songs, they would cease to function. They would become as silent as a corpse in a casket.FeedUnfurl
NotesOver the past month I’ve been exploring the rapidly evolving world of Large Language Models (LLM). It’s now accessible enough to run a LLM on a Raspberry Pi smarter than the original ChatGPT (November 2022). A modest desktop or laptop supports even smarter AI. It’s also private, offline, unlimited, and registration-free. The technology is improving at breakneck speed, and information is outdated in a matter of months. This article snapshots my practical, hands-on knowledge and experiences — information I wish I had when starting. Keep in mind that I’m a LLM layman, I have no novel insights to share, and it’s likely I’ve misunderstood certain aspects. In a year this article will mostly be a historical footnote, which is simultaneously exciting and scary.FeedUnfurl
NotesI’ve been having quite a bit of fun with the fairly recent LivePortrait model, generating deepfakes of my friends for some cheap laughs.FeedUnfurl
Notes Large language models (LLMs) have shown remarkable proficiency in generating text, benefiting from extensive training on vast textual corpora. However, LLMs may also acquire unwanted behaviors from the diverse and sensitive nature of their training data, which can include copyrighted and private content. Machine unlearning has been introduced as a viable solution to remove the influence of such problematic content without the need for costly and time-consuming retraining. This process aims to erase specific knowledge from LLMs while preserving as much model utility as possible. Despite the effectiveness of current unlearning methods, little attention has been given to whether existing unlearning methods for LLMs truly achieve forgetting or merely hide the knowledge, which current unlearning benchmarks fail to detect. This paper reveals that applying quantization to models that have undergone unlearning can restore the "forgotten" information. To thoroughly evaluate this phenomenon, we conduct comprehensive experiments using various quantization techniques across multiple precision levels. We find that for unlearning methods with utility constraints, the unlearned model retains an average of 21\% of the intended forgotten knowledge in full precision, which significantly increases to 83\% after 4-bit quantization. Based on our empirical findings, we provide a theoretical explanation for the observed phenomenon and propose a quantization-robust unlearning strategy to mitigate this intricate issue... Unfurl
NotesIt is nightmarish to me to read reports of how reliant on ChatGPT students have become, even outsourcing to the machines the ideally very personal assignment "briefly introduce yourself and say what you're hoping to get out of this class." It is depressing to me to read defenses of those students, particularly this one that compares an AI-written essay to using a washing machine in that it reduces the time required for the labor. This makes sense only if the purpose of a student writing an essay is "to have written an essay," which it is not. The teacher did not assign it as busywork. The purpose of an essay is to learn and practice communication skills, critical thinking, organization of one's own thoughts. These are useful skills to develop, even (especially!) if you do not go into a writing career. Unfurl
NotesOasis takes in user keyboard input and generates real-time gameplay, including physics, game rules, and graphics. You can move around, jump, pick up items, break blocks, and more. There is no game engine; just a foundation model.Unfurl
NotesGenerative AI is like if capitalism reinvented the fae. It’ll trick you into accepting its agreement and then it’ll steal your face and start speaking with your voice.EmbedUnfurl
NotesHey everyone! Today I wanted to talk about the state of the internet, how artists and everyone is affected by AI slop and social media, and why I think everyone should have a personal website these days! Let's bring back the old school internet in new, fun, and creative ways! ^_^EmbedUnfurl
 The 70% problem: Hard truths about AI-assisted coding
The 70% problem: Hard truths about AI-assisted coding Godot Isn't Making it
Godot Isn't Making it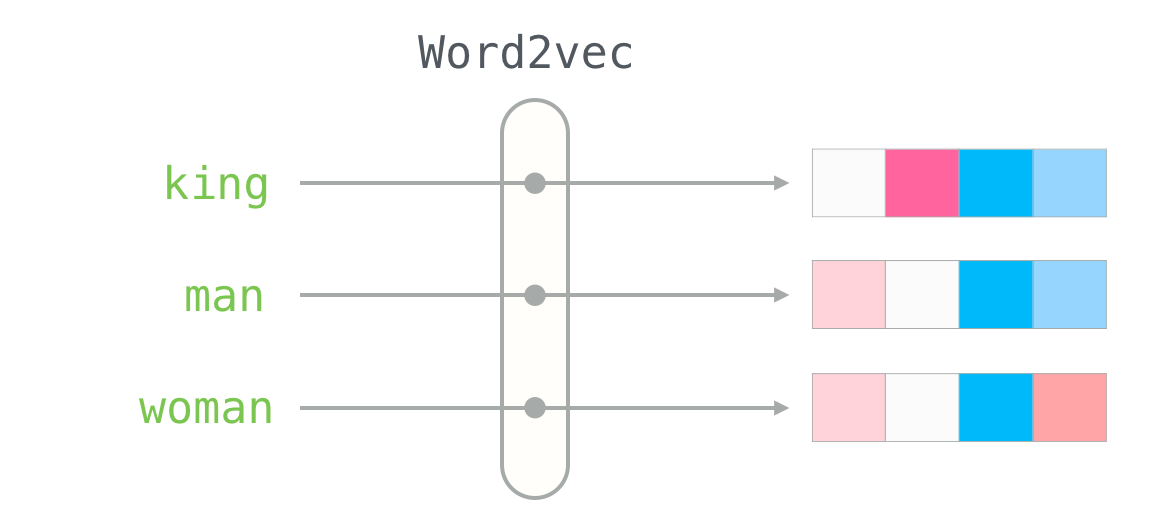 The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time.
The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time. Bluesky, AI, and the battle for consent on the open web
Bluesky, AI, and the battle for consent on the open web Hackerrank was broken - but now it's actually harmful — segfaulte
Hackerrank was broken - but now it's actually harmful — segfaulte Between the Booms: AI in Winter – Communications of the ACM
Between the Booms: AI in Winter – Communications of the ACM Adjacent Possible | Steven Johnson | Substack
Adjacent Possible | Steven Johnson | Substack You Exist In The Long Context
You Exist In The Long Context An introduction to fine-tuning LLMs at home with Axolotl • The Register
An introduction to fine-tuning LLMs at home with Axolotl • The Register As public perception of AI sours, crowdfunding platforms scramble | Polygon
As public perception of AI sours, crowdfunding platforms scramble | Polygon Sponsoring the Web Applets project, an open approach to AI-empowered web apps - Mozilla Innovations
Sponsoring the Web Applets project, an open approach to AI-empowered web apps - Mozilla Innovations Dead Labor, Dead Speech - by Nicholas Carr
Dead Labor, Dead Speech - by Nicholas Carr Perceptually lossless (talking head) video compression at 22kbit/s | Martin Lumiste
Perceptually lossless (talking head) video compression at 22kbit/s | Martin Lumiste [2410.16454] Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge
[2410.16454] Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge Whatever AI Looks Like, It's Not | Defector
Whatever AI Looks Like, It's Not | Defector Oasis
Oasis