NotesRight now, I’m not overly excited by MCP over “standard” tool calling. I much prefer agents.json and the concepts around endpoint discovery, which feel much more natural if you are working with APIs.FeedUnfurl
Notes"Vibe Coding" might get you 80% the way to a functioning concept. But to produce something reliable, secure, and worth spending money on, you’ll need experienced humans to do the hard work not possible with today’s models.Unfurl
NotesOne consistent pattern I’ve observed in the past year, since I published "The death of the junior developer", is that junior developers have actually been far more eager to adopt AI than senior devs. It’s not always true; a few folks have told us that their juniors are scared to use it because they think, somewhat irrationally, that it will take their jobs. (See: Behavioral regret theory. Thanks for the pointer Dr. Daniel Rock!)FeedUnfurl
NotesUsing LLMs to write code is difficult and unintuitive. It takes significant effort to figure out the sharp and soft edges of using them in this way, and there’s precious little guidance to help people figure out how best to apply them.
If someone tells you that coding with LLMs is easy they are (probably unintentionally) misleading you. They may well have stumbled on to patterns that work, but those patterns do not come naturally to everyone.
I’ve been getting great results out of LLMs for code for over two years now. Here’s my attempt at transferring some of that experience and intution to you.FeedUnfurl
NotesA native macOS app that allows users to chat with a local LLM that can respond with information from files, folders and websites on your Mac without installing any other software. Powered by llama.cpp. Unfurl
NotesThe first company to get this will own the next phase of AI development tools. They’ll build tools for real software instead of toys. They’ll make everything available today look like primitive experiments.FeedUnfurl
NotesWelcome to Boomer Prompts—an affectionate trip down memory lane of the elaborate, quirky, and sometimes overkill techniques used to guide earlier Large Language Models.
These “relics” showcase just how much LLMs have evolved—where once you needed to triple your instructions and role-play as a wise oracle, now simpler, more direct prompts suffice. Read on for a chuckle, and discover how far we’ve come!Unfurl
NotesWe’re shipping a new API in Firefox Nightly that will let you use our Firefox AI runtime to run offline machine learning tasks in your web extension.FeedEmbedUnfurl
NotesConcluding, I think this is a very interesting way of working with AI inference in the browser. The obvious downside is that you need to convince your users to download an extension, but the obvious upside is that you possibly can save them from having to download a model they may already have downloaded and stored on their disk. FeedUnfurl
NotesTimeline algorithms should be useful for people, not for companies. Their quality should not be evaluated in terms of how much more time people spend on a platform, but rather in terms of how well they serve their users’ purposesFeedUnfurl
NotesBy focusing on the answer correctness as a key success metric, and designing our datasets and metrics carefully, we’ve managed to build a reliable evaluation process which has helped us increase confidence in our system’s quality.FeedEmbedUnfurl
NotesTransformer Lab is a free, open-source LLM workspace that you can run on your own computer. It is designed to go beyond what most modern open LLM applications allow. Using Transformer Lab you can easily finetune, evaluate, export and test LLMs across different inference engines and platforms.FeedUnfurl
Notesllm-mlx is a brand new plugin for my LLM Python Library and CLI utility which builds on top of Apple’s excellent MLX array framework library and mlx-lm package. If you’re a terminal user or Python developer with a Mac this may be the new easiest way to start exploring local Large Language Models.FeedUnfurl
NotesTo me, all signs point towards software engineering changing radically as a profession to be much more oriented around the what and why of software, and much less around the how. This will cause disruption at a massive scale in the long run. But in the short run, it's just a lot of fun to play with these tools and see what they can do.Unfurl
NotesIt is surprisingly straightforward to increase the VRAM of your Mac (Apple Silicone M1/M2/M3 chips) computer and use it to load large language models. Here’s the rundown of my experiments. ... I found a way to bypass this limitation. To allocate more of your Mac’s system RAM to VRAM – in this case, up to 28 GB – the following command can be used in the terminal window:
sudo sysctl iogpu.wired_limit_mb=27536FeedEmbedUnfurl
Notesmy attempt to build such a capable AI computer without spending too much. I ended up with a workstation with 48GB of VRAM that cost me around 1700 eurosFeedUnfurl
NotesYou wrote an interesting comment about getting your work into the LLM training corpus: "there has never been a more vital hinge-y time to write."
Do you mean that in the sense that you will be this drop in the bucket that’s steering the Shoggoth one way or the other? Or do you mean it in the sense of making sure your values and persona persist somewhere in latent space?FeedEmbedUnfurl
NotesPersonally, I feel like I get a lot of value from AI. I think many of the people who don’t feel this way are “holding it wrong”: i.e. they’re not using language models in the most helpful ways. In this post, I’m going to list a bunch of ways I regularly use AI in my day-to-day as a staff engineer.FeedUnfurl
NotesUndoubtedly, the sloppification of the internet will likely get worse over the next few years. And as such, the returns to curating quality sources of content will only increase. My advice? Use an RSS feed reader, read Twitter lists instead of feeds, and find spaces where real discussion still happens (e.g. LessWrong and Lobsters still both seem slop-free).Unfurl
NotesAt the same time, there should be some humility about the fact that earlier iterations of the chip ban seem to have directly led to DeepSeek’s innovations. Those innovations, moreover, would extend to not just smuggled Nvidia chips or nerfed ones like the H800, but to Huawei’s Ascend chips as well. Indeed, you can very much make the case that the primary outcome of the chip ban is today’s crash in Nvidia’s stock price.Unfurl
NotesPeople with less knowledge about AI are actually more open to using the technology. We call this difference in adoption propensity the “lower literacy-higher receptivity” link.Unfurl
NotesI feel like half of my social media feed is composed of AI grifters saying software developers are not going to make it. Combine that sentiment with some economic headwinds and it's easy to feel like we're all screwed. I think that's bullshit. The best days of our industry lie ahead.Unfurl
NotesJust as Midas discovered that turning everything to gold wasn't always helpful, we'll see that blindly applying cosine similarity to vectors can lead us astray. While embeddings do capture similarities, they often reflect the wrong kind - matching questions to questions rather than questions to answers, or getting distracted by superficial patterns like writing style and typos rather than meaning. This post shows you how to be more intentional about similarity and get better results.
NotesThe Switch runs an off-the-shelf Nvidia Tegra X1 with 4GB of RAM. It was Nvidias second desktop GPU architecture in a mobile chip, after the Nvidia Tegra K1, containing 256 Maxwell CUDA cores. Announced ten years ago now (On January 5, 2015) it was originally intended for tablets and the automotive industry, before Nintendo picked it up. The Jetson TX1 dev kit was released and it was also present in the somewhat popular and well-known Jetson Nano (though with only half the CUDA cores enabled.) A fully functional (albeit largely proprietary, in traditional Nvidia fashion) Linux4Tegra distribution was shipped, with a working CUDA development environment.
CUDA? The compute platform that’s driving the AI revolution ✨? In my Nintendo Switch?
Surely you see where I’m going with this.FeedEmbedUnfurl
NotesThis document is a summary of my personal experiences using generative models while programming over the past year. It has not been a passive process. I have intentionally sought ways to use LLMs while programming to learn about them. The result has been that I now regularly use LLMs while working and I consider their benefits net-positive on my productivity. (My attempts to go back to programming without them are unpleasant.)FeedUnfurl
NotesWelcome to OpenHands (formerly OpenDevin), a platform for software development agents powered by AI.
OpenHands agents can do anything a human developer can: modify code, run commands, browse the web, call APIs, and yes—even copy code snippets from StackOverflow.Unfurl
NotesAI isn't making our software dramatically better because software quality was (perhaps) never primarily limited by coding speed. The hard parts of software development – understanding requirements, designing maintainable systems, handling edge cases, ensuring security and performance – still require human judgment.
What AI does do is let us iterate and experiment faster, potentially leading to better solutions through more rapid exploration. But only if we maintain our engineering discipline and use AI as a tool, not a replacement for good software practices. Remember: The goal isn't to write more code faster. It's to build better software. Used wisely, AI can help us do that. But it's still up to us to know what "better" means and how to achieve it.FeedUnfurl
NotesNew, more powerful chips require entirely new methods to rack-mount, operate and cool them, and all of these parts must operate in sync, as overheating GPUs will die. While these units are big, some of their internal components are microscopic in size, and unless properly cooled, their circuits will start to crumble when roasted by a guy typing "Garfield with Gun" into ChatGPT.FeedUnfurl
NotesI hope that you now have a sense for word embeddings and the word2vec algorithm. I also hope that now when you read a paper mentioning “skip gram with negative sampling” (SGNS) (like the recommendation system papers at the top), that you have a better sense for these concepts.FeedUnfurl
NotesSo the problem Bluesky is dealing with is not so much a problem with Bluesky itself or its architecture, but one that’s inherent to the web itself and the nature of building these training datasets based on publicly-available data. Van Strien’s original act clearly showed the difference in culture between AI and open social web communities: on the former it’s commonplace to grab data if it can be read publicly (or even sometimes if it’s not), regardless of licensing or author consent, while on open social networks consent and authors’ rights are central community norms.FeedUnfurl
NotesSo, in summary: maybe people shy away from copilots because they’re tired of complexity, they’re tired of accelerating productivity without improving hours, they’re afraid of forgetting rote skills and basic knowledge, and they want to feel like writers, not managers.
Maybe some or none of these things are true - they’re emotional responses and gut feelings based on predictions - but they matter nonetheless.FeedUnfurl
NotesA newsletter from author Steven Johnson exploring where good ideas come from—and how to keep them from turning against us. Click to read Adjacent Possible, by Steven Johnson, a Substack publication with tens of thousands of subscribers.FeedUnfurl
NotesThe current state-of-the-art Gemini model can fit roughly 1.5 million words in its context. That’s enough for me to upload the full text of all fourteen of my books, plus every article, blog post, or interview I’ve ever published—and the entirety of my collection of research notes that I’ve compiled over the years. The Gemini team has announced plans for a model that could hold more than 7 million words in its short-term memory. That’s enough to fit everything I’ve ever written, plus the hundred books and articles that most profoundly shaped my thinking over the years. An advanced model capable of holding in focus all that information would have a profound familiarity with all the words and ideas that have shaped my personal mindset. Certainly its ability to provide accurate and properly-cited answers to questions about my worldview (or my intellectual worldview, at least) would exceed that of any other human. In some ways it would exceed my own knowledge, thanks to its ability to instantly recall facts from books I read twenty years ago, or make new associations between ideas that I have long since forgotten. It would lack any information about my personal or emotional history—though I suppose if I had maintained a private journal over the past decades it would be able to approximate that part of my mindset as well. But as reconstruction of my intellectual grounding, it would be unrivaled. If that is not considered material progress in AI, there is something wrong with our metrics.Unfurl
NotesIn this guide we'll discuss:
Where and when fine-tuning can be useful.
Alternative approaches to extending the capabilities and behavior of pre-trained models.
The importance of data preparation.
How to fine-tune Mistral 7B using your own custom dataset with Axolotl.
The many hyperparameters and their effect on training.
Additional resources to help you fine-tune your models faster and more efficiently.FeedUnfurl
NotesIf, as Marx argued, capital is dead labor, then the products of large language models might best be understood as dead speech. Just as factory workers produce, with their “living labor,” machines and other forms of physical capital that are then used, as “dead labor,” to produce more physical commodities, so human expressions of thought and creativity—“living speech” in the forms of writing, art, photography, and music—become raw materials used to produce “dead speech” in those same forms. LLMs, to continue with Marx’s horror-story metaphor, feed “vampire-like” on human culture. Without our words and pictures and songs, they would cease to function. They would become as silent as a corpse in a casket.FeedUnfurl
NotesOver the past month I’ve been exploring the rapidly evolving world of Large Language Models (LLM). It’s now accessible enough to run a LLM on a Raspberry Pi smarter than the original ChatGPT (November 2022). A modest desktop or laptop supports even smarter AI. It’s also private, offline, unlimited, and registration-free. The technology is improving at breakneck speed, and information is outdated in a matter of months. This article snapshots my practical, hands-on knowledge and experiences — information I wish I had when starting. Keep in mind that I’m a LLM layman, I have no novel insights to share, and it’s likely I’ve misunderstood certain aspects. In a year this article will mostly be a historical footnote, which is simultaneously exciting and scary.FeedUnfurl
Notes Large language models (LLMs) have shown remarkable proficiency in generating text, benefiting from extensive training on vast textual corpora. However, LLMs may also acquire unwanted behaviors from the diverse and sensitive nature of their training data, which can include copyrighted and private content. Machine unlearning has been introduced as a viable solution to remove the influence of such problematic content without the need for costly and time-consuming retraining. This process aims to erase specific knowledge from LLMs while preserving as much model utility as possible. Despite the effectiveness of current unlearning methods, little attention has been given to whether existing unlearning methods for LLMs truly achieve forgetting or merely hide the knowledge, which current unlearning benchmarks fail to detect. This paper reveals that applying quantization to models that have undergone unlearning can restore the "forgotten" information. To thoroughly evaluate this phenomenon, we conduct comprehensive experiments using various quantization techniques across multiple precision levels. We find that for unlearning methods with utility constraints, the unlearned model retains an average of 21\% of the intended forgotten knowledge in full precision, which significantly increases to 83\% after 4-bit quantization. Based on our empirical findings, we provide a theoretical explanation for the observed phenomenon and propose a quantization-robust unlearning strategy to mitigate this intricate issue... Unfurl
NotesIt is nightmarish to me to read reports of how reliant on ChatGPT students have become, even outsourcing to the machines the ideally very personal assignment "briefly introduce yourself and say what you're hoping to get out of this class." It is depressing to me to read defenses of those students, particularly this one that compares an AI-written essay to using a washing machine in that it reduces the time required for the labor. This makes sense only if the purpose of a student writing an essay is "to have written an essay," which it is not. The teacher did not assign it as busywork. The purpose of an essay is to learn and practice communication skills, critical thinking, organization of one's own thoughts. These are useful skills to develop, even (especially!) if you do not go into a writing career. Unfurl
NotesI released LLM 0.17 last night, the latest version of my combined CLI tool and Python library for interacting with hundreds of different Large Language Models such as GPT-4o, Llama, Claude and Gemini.FeedUnfurl
NotesWe have entered an era of LLM democratization. By showing that smaller models can be highly effective, enabling easy experimentation, diversifying control, and providing incentives that are not profit motivated, open-source initiatives are moving us into a more dynamic and inclusive AI landscape. This doesn’t mean that some of these models won’t be biased, or wrong, or used to generate disinformation or abuse. But it does mean that controlling this technology is going to take an entirely different approach than regulating the large players.FeedEmbedUnfurl
NotesBut in calling these programs “artificial intelligence” we grant them a claim to authorship that is simply untrue. Each of those tokens used by programs like ChatGPT—the “language” in their “large language model”—represents a tiny, tiny piece of material that someone else created. And those authors are not credited for it, paid for it or asked permission for its use. In a sense, these machine-learning bots are actually the most advanced form of a chop shop: They steal material from creators (that is, they use it without permission), cut that material into parts so small that no one can trace them and then repurpose them to form new products.Unfurl
 Notes on MCP - Tao of Mac
Notes on MCP - Tao of Mac Revenge of the junior developer | Sourcegraph Blog
Revenge of the junior developer | Sourcegraph Blog Verifiability is the Limit
Verifiability is the Limit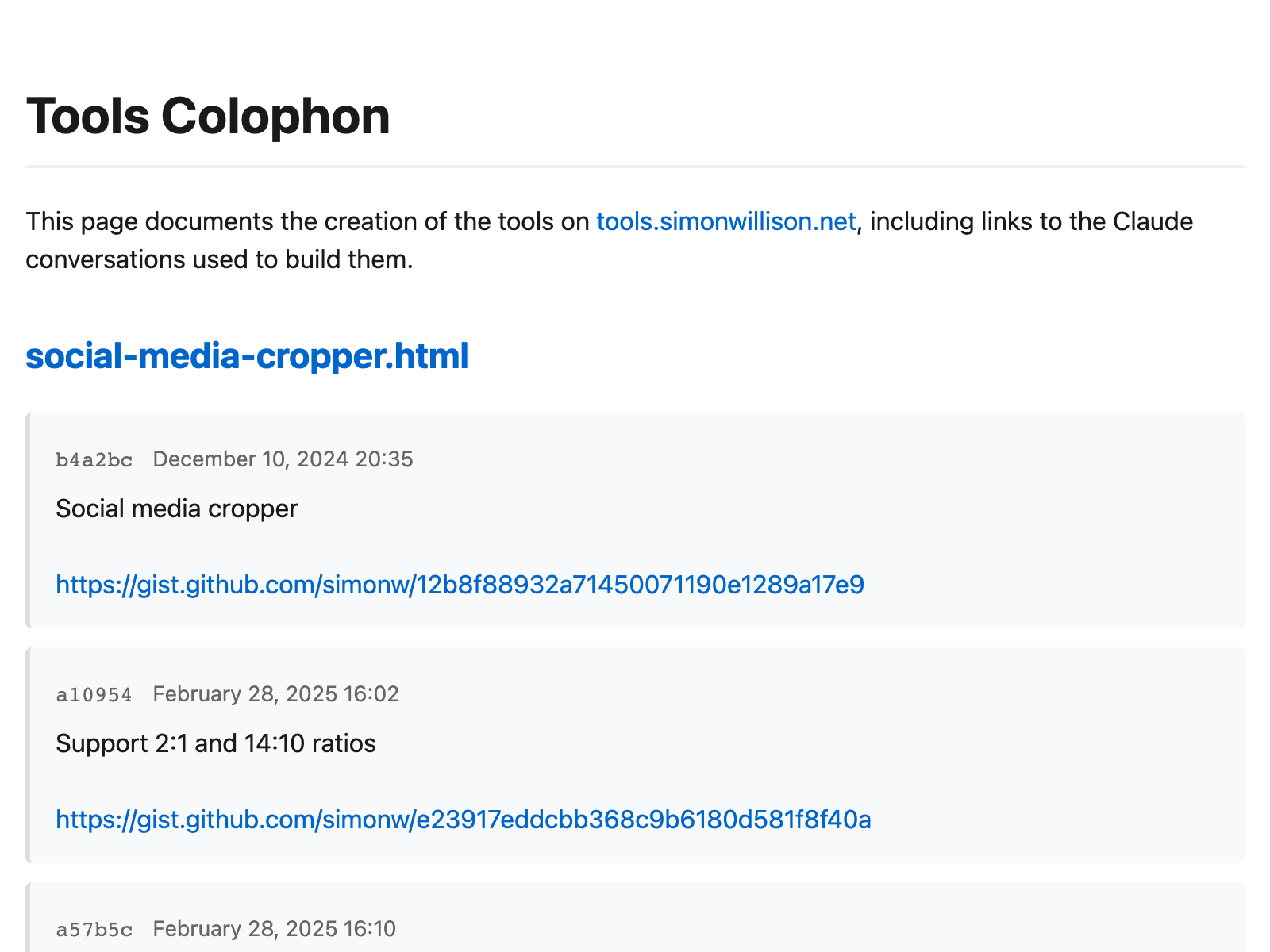 Here’s how I use LLMs to help me write code
Here’s how I use LLMs to help me write code What if AGI is Free? | Drew Breunig
What if AGI is Free? | Drew Breunig Running inference in web extensions
Running inference in web extensions FOSDEM 2025 - Build your own timeline algorithm
FOSDEM 2025 - Build your own timeline algorithm Evaluating Retrieval Augmented Generation for large-scale codebases
Evaluating Retrieval Augmented Generation for large-scale codebases Getting Started | Transformer Lab
Getting Started | Transformer Lab My LLM codegen workflow atm | Harper Reed's Blog
My LLM codegen workflow atm | Harper Reed's Blog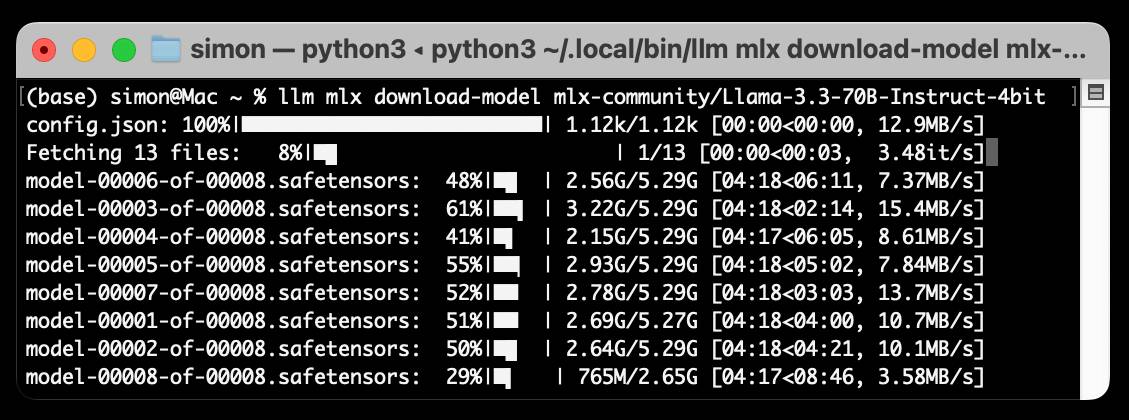 Run LLMs on macOS using llm-mlx and Apple’s MLX framework
Run LLMs on macOS using llm-mlx and Apple’s MLX framework How to Increase the VRAM of Your Mac with Apple Silicone for LLMs? | Hardware Corner
How to Increase the VRAM of Your Mac with Apple Silicone for LLMs? | Hardware Corner ewintr.nl - building a personal, private ai computer on a budget
ewintr.nl - building a personal, private ai computer on a budget Gwern Branwen - How an Anonymous Researcher Predicted AI's Trajectory
Gwern Branwen - How an Anonymous Researcher Predicted AI's Trajectory AI Slop, Suspicion, and Writing Back | Ben Congdon
AI Slop, Suspicion, and Writing Back | Ben Congdon DeepSeek FAQ – Stratechery by Ben Thompson
DeepSeek FAQ – Stratechery by Ben Thompson Knowing less about AI makes people more open to having it in their lives – new research
Knowing less about AI makes people more open to having it in their lives – new research Ignore the Grifters - AI Isn't Going to Kill the Software Industry — Dustin Ewers
Ignore the Grifters - AI Isn't Going to Kill the Software Industry — Dustin Ewers Switch AI ✨ – Insane Rambles About Technology
Switch AI ✨ – Insane Rambles About Technology The 70% problem: Hard truths about AI-assisted coding
The 70% problem: Hard truths about AI-assisted coding Godot Isn't Making it
Godot Isn't Making it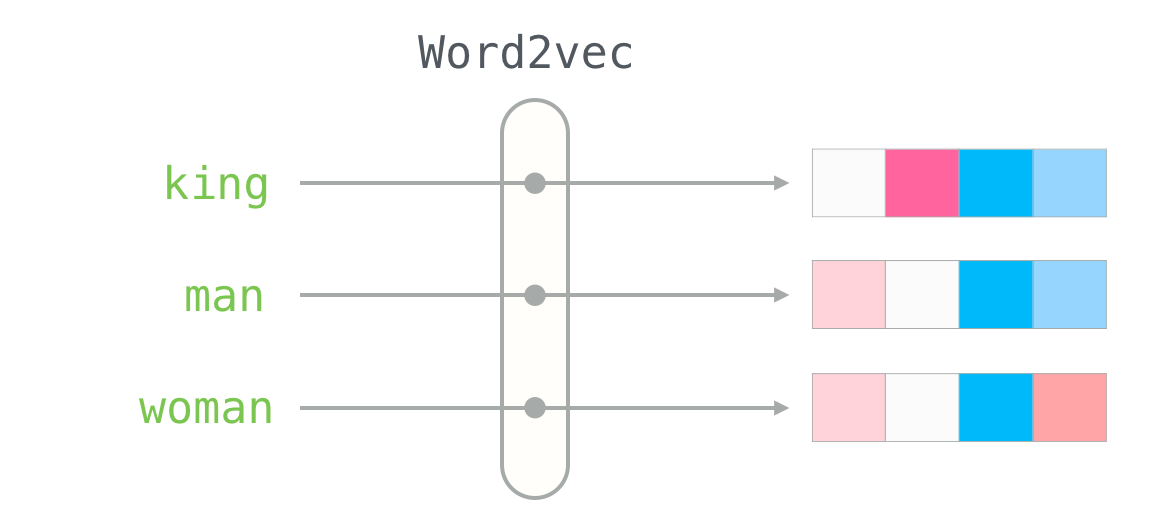 The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time.
The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time. Bluesky, AI, and the battle for consent on the open web
Bluesky, AI, and the battle for consent on the open web Adjacent Possible | Steven Johnson | Substack
Adjacent Possible | Steven Johnson | Substack You Exist In The Long Context
You Exist In The Long Context An introduction to fine-tuning LLMs at home with Axolotl • The Register
An introduction to fine-tuning LLMs at home with Axolotl • The Register Dead Labor, Dead Speech - by Nicholas Carr
Dead Labor, Dead Speech - by Nicholas Carr [2410.16454] Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge
[2410.16454] Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge Whatever AI Looks Like, It's Not | Defector
Whatever AI Looks Like, It's Not | Defector You can now run prompts against images, audio and video in your terminal using LLM
You can now run prompts against images, audio and video in your terminal using LLM Open-Source LLMs - Schneier on Security
Open-Source LLMs - Schneier on Security ChatGPT is not ‘artificial intelligence.’ It’s theft. | America Magazine
ChatGPT is not ‘artificial intelligence.’ It’s theft. | America Magazine